本文是上周 Tubi TV 在北京举办「Elixir Meetup 第二期」分享之 <从 Django 到 Phoenix + Absinthe> 的部分内容文字稿。
什么是 GraphQL
A query language for your API
按照 GraphQL 官方的解释,它无非就是一种用于 api 的查询语言而已。
拿这个查询所有文章的 title 和 slug 的例子来说
query {
articles {
title
slug
}
}
它返回的数据是这个
{
"data": {
"articles": [
{
"slug": "article-test",
"title": "Article test"
},
{
"slug": "article-test2",
"title": "Article test2"
}
]
}
}
而翻译成 http 请求,其实就是
$ http POST http://127.0.0.1:4000/api query="{articles { title slug } }"
或
$ http http://127.0.0.1:4000/api?\query\=\{articles\{title%20slug\}\}
如果你不了解 GraphQL,你可以暂时把它理解成带有特殊参数或特殊 body 的 HTTP 请求, 这三个特殊的参数一般情况下是 query/operationName/variables。
GraphQL 相对 rest 等有什么优势
最大的优势是灵活,前端需要什么数据,便传什么字段,自由组合,这时决定最终数据结构的不再是后端,而是前端。而这种灵活同时带来了其他优势,如:性能,拿的数据都是前端想要的,相比 rest 等少了大量冗余数据,传输速度自然加快了;另外一点我个人感触较深的的则是开发速度,作为一个后端,当你的类型系统设计好之后,之后接到的大部分需求,其实很多知识对 type 一些组合而已,所以用了 GraphQl 之后,你不再需要针对每个客户端单独再写一套接口。
为什么选择 Absinthe
Absinthe 是 Elixir 下的一个 GraphQl 工具包。选择 Absinthe,其实有好几个原因,其一是跟 Ecto/Phonnix 的无缝连接,其二则是 Absinthe 自身的确好用。
Ecto
Ecto 极其简洁,无论是 (LINQ)Language Integrated Query 语法还是 Pipeline 的语法。
LINQ 例子
from q in Article, where: q.user_id == ^user_id
Pipeline 语法
Article |> where([q], q.id == ^user_id)
这种语法让写惯 SQL 的后端毫无负担。
Ecto 特别清晰,用其他语言的 ORM 时,你可以需要去记一些规则会避免数据库重复 hit 的性能问题,而在 Ecto 里面,你只需要知道只有 Repo.function 才会 hit db,而在所有 Repo.function 之前的操作,都只是 query 的组合而已。
Ecto 的可组合能力特别强,尤其是 Ecto 3.0 支持 named binding 之后,组合起来更加方便了。所以你可以经常看到这种查询语句,如查询艺术家的名称和专辑名称,并且只查 Miles Davis 一个人的。
albums_by_miles = from a in "albums", as: "albums", join: ar in "artists", as: "artists", on: a.artist_id == ar.id, where: ar.name == "Miles Davis"
album_query = from [artists: ar, albums: a] in albums_by_miles, select: [a.title, ar.name]
Absinthe
另一个原因则是 Absinthe 自身,首先,Absinthe 没有太多陌生的概念或语法,如 Schema/object/field/resolve 等是极其好理解的,所以如果你有过 Python 或 Ruby 或 Elixir 的经验,那么上手是极快的;其次,Absinthe 的工具链很完善,如果 absinthe_relay 解决分页问题,dataloader 解决 n+1 问题;其三,Absinthe 是 ELixir 下的,扩展非常方便。
用 Absinthe 践行 GraphQL
Absinthe GraphQL 的项目结构
用过 Phoenix 的人都知道,Phoenix router 里面可以通过 Plug 的组合,定义一系列的管道去处理一些通用的问题,而在 absinthe 里,其实也有一堆 phases 组成了管道。

这个图只是对 phases 的一个简化,事实上现在的 absinthe 管道里的 phases 已经有几十个。而这里面我们最应该关心的其实是三种,parse, validate,以及 execute。parse 顾名思义关系到你如何定义 schema,用何种方式定义 schema,而 validate 其实是对在 parse 之后的 ast 做验证,比如验证输入的 field 是否存在,格式是否正确等等?这个特性我们可以用来编写一些自定义的 type,而 execute 也就是我们上图的 resolve 和 build result phases,它遍历整个 ast, 执行我们编写的 resolvers,整合结果。我们编写的大部分代码,其实都发生在这类 phases 里.
看个具体的例子。
query {
articles {
title
comments {
body
}
author {
username
}
}
}
这个 query 其实会被 parse 成这样
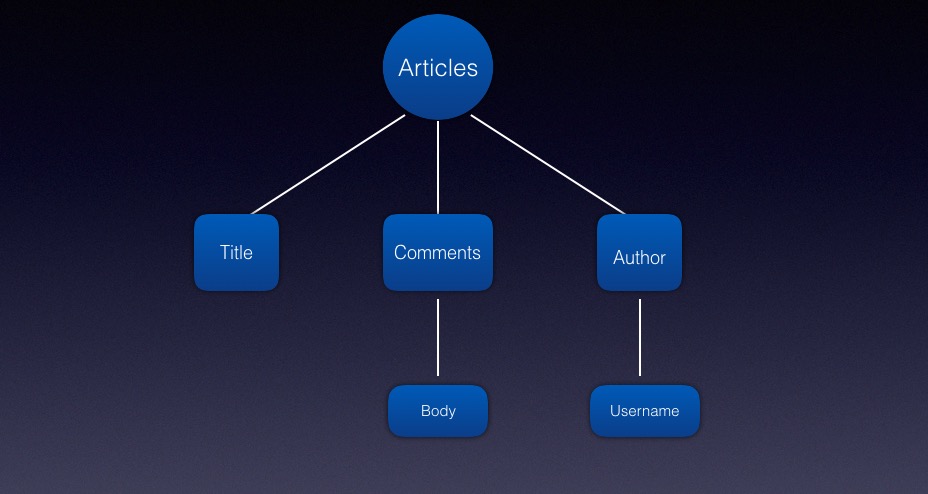
query parse 成这样后,execute phases 首先会解析 articles 这一层,拿到所有 article 之后,再解析 title 这一层,当 comments 里的字段和 author 的字段都解析完了,最终会合并一个结果出来。
那么在 absinthe 里如何实现这样的一个 query 呢?
Absinthe 具体怎么做的?
defmodule RealWorldWeb.Schema do
use Absinthe.Schema
alias RealWorld.Blog
query do
field :articles, list_of(:article) do
resolve fn _, args, _info ->
{:ok, Blog.list_articles(args)}
end
end
end
object :profile do
field :username, :string
field :bio, :string
field :image, :string
end
object :comment do
field :body, :string
end
object :article do
field :title, :string
field :comments, list_of(:comment)
field :author, :profile
end
end
这样其实已经差不多了,当然了,这样返回的数据,会有些缺失,因为 Blog.list_articles 返回的是一个列表,而这个列表里的对象缺失了 author 和 comment 字段。我们的原始大概是这样的。
real_world_dev=# select * from articles;
id | title | description | body | slug | created_at | updated_at | user_id | tag_list
----+--------------+-------------+-----------+--------------+---------------------+---------------------+---------+-------------
1 | some title 1 | | some body | some-title-1 | 2019-11-20 06:53:48 | 2019-11-20 06:53:48 | 1 | {tag1,tag2}
2 | some title 2 | | some body | some-title-2 | 2019-11-20 06:53:48 | 2019-11-20 06:53:48 | 3 | {tag1,tag2}
(2 rows)
你可以看到里面只有 user_id 但没有 author 字段。Graphql 有个 resolve 原则就是,如果你没有指定解析函数, 那么会有一个默认的解析函数,这个默认解析函数会以字段名做 key 从 parent object 中,取不到则返回 null。所以这时我们需要加上两个解析函数。
defmodule RealWorldWeb.Schema do
use Absinthe.Schema
import Ecto.Query, only: [from: 2]
alias RealWorld.Blog
alias RealWorld.Repo
alias RealWorld.Blog.{Comment, Article}
alias RealWorld.Accounts.User
query do
field :articles, list_of(:article) do
resolve fn _, args, _info ->
{:ok, Blog.list_articles(args)}
end
end
end
object :profile do
field :username, :string
field :bio, :string
field :image, :string
end
object :comment do
field :body, :string
end
object :article do
field :title, :string
field :comments, list_of(:comment) do
resolve fn parent, _args, _info ->
{:ok,
from(c in Comment, join: a in assoc(c, :article), where: a.id == ^parent.id)
|> Repo.all()}
end
end
field :author, :profile do
resolve fn parent, _args, _info ->
{:ok,
from(q in User,
join: a in Article,
on: a.user_id == q.id,
where: a.id == ^parent.id
)
|> Repo.one()}
end
end
end
end
你可能会觉得有点奇怪,就这么短短 50 行代码。对,如果仅仅是实现刚刚提到的简单的业务功能,这 50 行的确是够了。但是我们日常工作中的业务明显不可能这么简单,比如我们有些特殊字段需要用户登录才能查看,另外上面的 query 也有 N+1 问题,先说说这个特殊字段。 比如文章可以收藏,可以点赞,那么列出一批文章,如何知道这篇文章,你是否赞过?显而易见,我们需要创建文章与用户的关联,比如创建一个表,这个表有 user_id 和 article_id 的字段。然后在 article 这个 type 加一个 field: favorited。加上之后 article 的类型大概是这样的。
object :article do
field :title, :string
field :favorited, :boolean do
resolve fn parent, _args, _info ->
do_something
end
end
field :comments, list_of(:comment) do
resolve fn parent, _args, _info ->
{:ok,
from(c in Comment, join: a in assoc(c, :article), where: a.id == ^parent.id)
|> Repo.all()}
end
end
field :author, :profile do
resolve fn parent, _args, _info ->
{:ok,
from(q in User,
join: a in Article,
on: a.user_id == q.id,
where: a.id == ^parent.id
)
|> Repo.one()}
end
end
end
这个 do_something 运行不了的,因为还缺失一个东西,就是 child field 怎么知道当前用户是啥呢?这里需要引入一个新的概念,就是任何语言实现的 GraphQL 解析函数都会接收到 4 个参数:
- parent 自身的结果,在这里是一个 article
- args resolve 宏下面 function 的第二个参数,主要用于 field 做一些过滤,可以通过在 field 和 resolve 插入 arg 宏实现
- field 的一些元信息,比如当前 field 是啥
- context 提供给所有 resolvers 的一个可变对象
Context
前三个参数都已提过,而 context 在 absinthe 中实现非常简单
# route.ex
pipeline :graphql do
plug :accepts, ["json"]
plug RealWorldWeb.Context
end
scope "/" do
pipe_through :graphql
forward "/api", Absinthe.Plug,
schema: RealWorldWeb.Schema
forward "/graphiql", Absinthe.Plug.GraphiQL,
schema: RealWorldWeb.Schema
end
然后实现一个 context plug
defmodule RealWorldWeb.Context do
@behaviour Plug
import Plug.Conn
def init(opts), do: opts
def call(conn, _) do
context = build_context(conn)
Absinthe.Plug.put_options(conn, context: context)
end
defp build_context(conn) do
with ["Bearer " <> token] <- get_req_header(conn, "authorization"),
{:ok, user, _claims} <- RealWorldWeb.Guardian.resource_from_token(token) do
%{current_user: user}
else
_ -> %{}
end
end
end
这里不理解 Plug 的机制没太大关系,他的核心功能其实就是 call 回调函数,这个回调函数接收一个 Plug.Conn 结构,输出的也是一个 Plug.Conn 结构。用过 phoenix 的人都知道 Plug.Conn 这个结构伴随了一个请求从始至终。而在 build_context 函数,调用了 Guardian 模块,他是 elixir 里面非常知名的一个 jwt 包。
加上这些代码之后,只要我们的请求的 headers 上带上了 Bearer 型的 authorization token,那么 absinthe 会自动在 resolution 里自动加上 context,意味着这时,你请求的所有字段的解析函数都能拿到 context 了。
object :article do
field :title, :string
field :favorited, :boolean do
resolve fn article, _args, %{context: %{current_user: user}} ->
query = from(f in Favorite, where: f.article_id == ^article.id and f.user_id == ^user.id)
case query |> Repo.one() do
%Favorite{} -> {:ok, true}
_ -> {:ok, false}
end
end
end
field :comments, list_of(:comment) do
resolve fn parent, _args, _info ->
{:ok,
from(c in Comment, join: a in assoc(c, :article), where: a.id == ^parent.id)
|> Repo.all()}
end
end
field :author, :profile do
resolve fn parent, _args, _info ->
{:ok,
from(q in User,
join: a in Article,
on: a.user_id == q.id,
where: a.id == ^parent.id
)
|> Repo.one()}
end
end
end
end
但是上面的代码会引发一个新的问题,就是用户没登录,同时又请求了 favorited 这个字段的话,那么服务器会抛 500。但你总不可能每个 resolver 函数都写个条件判断有没登录吧,这个时候最好的解决方式就是使用中间件。
Middleware
同样的,在 absinthe 上实现一个 middleware 也很简单。
defmodule RealWorldWeb.Schema.Middleware.Authenticate do
@behaviour Absinthe.Middleware
def call(resolution, _) do
case resolution.context do
%{current_user: _} ->
resolution
_ ->
resolution
|> Absinthe.Resolution.put_result({:error, "Please sign in first!"})
end
end
end
这个中间件的 middleware 接收两个参数,一是 resolution,二是 middleware 的 config,我们刚刚提到的 4 个参数都会在 resolution 里面,回忆一下,是 parent, args, context, field infomation, 同时 resolution 还可以直接抛出结果。利用这个特性,我们只需要引入 middleware,加在 field 和 resolve 之间即可。
field :favorited, :boolean do
middleware Middleware.Authenticate
resolve fn article, _args, %{context: %{current_user: user}} ->
query = from(f in Favorite, where: f.article_id == ^article.id and f.user_id == ^user.id)
case query |> Repo.one() do
%Favorite{} -> {:ok, true}
_ -> {:ok, false}
end
end
end
上面是一个简单的访问鉴权的例子,甚至你还可以用它做复杂的数据鉴权。比如结合 parent 和 current_user,你可以再写个数据鉴权,middleware 可以多个结合使用,按顺序执行,而且 middleware 不仅可以用于 resolve 前,也可以放在 resolve 后。
N + 1 problem
接下来我们说说 n+1 问题,首先明确下什么是 n+1 问题,他其实主要指的请求一个带有子字段的列表型 type 时,一次获取列表,然后 n 次获取子字段。而我们这个 query
query {
articles {
title
comments {
body
}
author {
username
}
favorited
}
}
分别是 comments, author, favorited, 假设我们总文章有 10 篇,那么就会请求一次获取文章列表,请求 10 次获取 comments, 10 次获取author,10 次获取 favorited,其实 3n + 1,31 次的数据库访问。
那怎么解决这个问题呢?Absinthe 其实有好几种解决方式。
batch
第一种方式就是用 Absinthe.Resolution.Helpers 里的 batch 函数,他的原理基本是 resolve 之前把聚合参数汇总起来,然后把汇总起来的参数传入执行自定义的 batch_func 有了结果后,resoler 函数再把结果取出。拿 author 举例,batch 的效果大概是这样的。
第一个参数是用元祖表示的 batch_func, 第二个参数,是需要汇总的东西. 第三个参数是个函数,用于定义如何取结果。
最后效果是这样的:
field :author, :profile do
resolve fn parent, _args, _info ->
batch({__MODULE__, :authors_by_id}, parent.user_id, fn batch_results ->
{:ok, Map.get(batch_results, parent.user_id)}
end)
end
end
def authors_by_id(_, ids) do
users = from(q in User, where: q.id in ^ids) |> Repo.all()
Map.new(users, fn user -> {user.id, user} end)
end
batch 的方式挺好的,解决了 n+1 问题,但是如果每个需要 batch 的 field 都写这么一个 batch_func 显得太啰嗦了。所以接下来我要介绍便是 dataloader 的方式。
Dataloader
首先 dataloader 是一种通用的批量获取数据的方法,在很多语言都有实现。absinthe 组织下有个专门的 dataloader 包,所以它不仅仅用在 GraphQL 上。
daloader 怎么实现呢?
首先我们新建一个 loader
loader = Dataloader.new
%Dataloader{options: [get_policy: :raise_on_error], sources: %{}}
然后我们新建一个 source
I❤iex|18|▶▶▶ source = Dataloader.Ecto.new(RealWorld.Repo)
%Dataloader.Ecto{
batches: %{},
default_params: %{},
options: [],
query: #Function<2.54030264/2 in Dataloader.Ecto.new/2>,
repo: RealWorld.Repo,
repo_opts: [],
results: %{},
run_batch: #Function<3.54030264/5 in Dataloader.Ecto.new/2>
}
这个 source 是方便我们使用 Ecto 的,是最常用的 source,实际上只要实现 Dataloader.Source 的协议,都可以做为 source, 可以看到在 source 里面有个 batches 的 key,它的 values 是个 map,还有 results, 这其实就是将要 batch 和生成 results 的地方
然后把 source 添加到 loader
I❤iex|19|▶▶▶ loader = loader |> Dataloader.add_source(RealWorld.Accounts, source)
%Dataloader{
options: [get_policy: :raise_on_error],
sources: %{
RealWorld.Accounts => %Dataloader.Ecto{
batches: %{},
default_params: %{},
options: [],
query: #Function<2.54030264/2 in Dataloader.Ecto.new/2>,
repo: RealWorld.Repo,
repo_opts: [],
results: %{},
run_batch: #Function<3.54030264/5 in Dataloader.Ecto.new/2>
}
}
}
add_source 这函数第一个参数是 loader, 第二个参数是 source 的名称,一般来讲我们都用 phoenix context 的模块名称,第三个则是 source。这有什么好处呢?其实你可以看到,这个 source 的 value 有 query 和 run_batch 两个 key,命名成 context 模块名,这样我们就能方便切分一些过滤之类或者一些自定义逻辑放在 phoenix contxt 里。
接下来我们查一下 article 的列表,然后 一个个添加进去
> [article1, article2] = RealWorld.Blog.list_articles(%{})
...
> loader = Dataloader.load(loader, RealWorld.Accounts, :author, article1)
...
> loader = Dataloader.load(loader, RealWorld.Accounts, :author, article2)
...
> loader = Dataloader.run(loader)
I❤iex|36|▶▶▶ loader Dataloader.run(loader)
[debug] QUERY OK source="users" db=2.8ms queue=12.1ms
SELECT u0."id", u0."email", u0."password", u0."username", u0."bio", u0."image", u0."created_at", u0."updated_at", u0."id" FROM "users" AS u0 WHERE (u0."id" = ANY($1)) [[3, 1]]
%Dataloader{
options: [get_policy: :raise_on_error],
sources: %{
RealWorld.Accounts => %Dataloader.Ecto{
batches: %{},
default_params: %{},
options: [],
query: #Function<2.54030264/2 in Dataloader.Ecto.new/2>,
repo: RealWorld.Repo,
repo_opts: [],
results: %{
{:assoc, RealWorld.Blog.Article, #PID<0.382.0>, :author,
RealWorld.Accounts.User,
%{}} => {:ok,
%{
[1] => %RealWorld.Accounts.User{
__meta__: #Ecto.Schema.Metadata<:loaded, "users">,
articles: #Ecto.Association.NotLoaded<association :articles is not loaded>,
bio: "I'm a programmer",
comments: #Ecto.Association.NotLoaded<association :comments is not loaded>,
created_at: ~N[2019-11-20 06:53:47],
email: "therealscottming@gmail.com",
id: 1,
image: nil,
password: "$2b$12$Svr.zRec39X/0dwDaE2AtuRNbAtzEfOomHdxfUd5iTotMgY3WcdGi",
updated_at: ~N[2019-11-20 06:53:47],
username: "scott"
},
...
你会发现 run 之后,loader 的 Accounts 这个 source 里面已经有 results 了,同时 batches 已经被清空。
然后从 loader 里面按需取出来即可。
loader |> Dataloader.get(RealWorld.Accounts, :author, article2)
loader |> Dataloader.get_many(RealWorld.Accounts, :author, [article1, article2])
知道了这个使用流程,那么只要在 resolve 前把数据 load 好就能避免 n+1 问题了,那么在 schema 里面使用呢?Absinthe 实现了 Dataloader 的中间件,而我们只需要在 resolve 里面通过 on_load 这个函数去调用他的中间件,而这个中间件就帮我们做了再 resolve 前 run 的事情。
首先我们需要再 phoenix 的 context module 里面定义好 source,然后在那个 resolve 间流转的哪个 ctx 里面添加上 loader 的 key/value, 这样我们便能使用 dataloader 了。
def data() do
Dataloader.Ecto.new(Repo, query: &query/2, run_batch: &run_batch/5)
end
def query(queryable, _) do
queryable
end
def run_batch(queryable, query, col, inputs, repo_opts) do
Dataloader.Ecto.run_batch(Repo, queryable, query, col, inputs, repo_opts)
en
def context(ctx) do
loader =
Dataloader.new()
|> Dataloader.add_source(Blog, Blog.data())
|> Dataloader.add_source(Accounts, Accounts.data())
Map.put(ctx, :loader, loader)
end
def plugins do
[Absinthe.Middleware.Dataloader] ++ Absinthe.Plugin.defaults()
end
最后我们 author 里面执行的内容大概是这样的
field :author, :profile do
resolve fn article, _args, %{context: %{loader: loader}} ->
loader
|> Dataloader.load(RealWorld.Accounts, :author, article)
|> on_load(fn loader ->
author = Dataloader.get(loader, RealWorld.Accounts, :author, article)
{:ok, author}
end)
end
end
end
显而易见地,这类代码很好抽象。所以 absinthe 提供了 helpers,也叫 dataloader, 最后我们这个 :author 的 field 其实这样的:
field :author, :profile, resolve: dataloader(Accounts)
这个 dataloader/1 实际上 dataloader/3 的一个简写,dataloader/3 需要 3 个参数,第 1 个是 source,第 2 个是 batch_key, 第三个则可以跟你定义的 args 合并的 map.
第 1 个和第 2 个参数,我们都讲过了,第三个参数非常有用。有的时候我们不希望在某个 type 下展示全部的关联数据,我们希望能做一些过滤,这个时候如果我们给 args 传入一个带有 scope 的 key 的 map(个人习惯用 scope),同时在 context 写个模式匹配的函数。那么 article 下的 comment 的数据就可以被过滤了。
field :comments, list_of(:comment) do
arg :author_name, :string
resolve dataloader(Blog, :comments, args: %{scope: :article})
end
def query(Comment, %{scope: :article} = args) do
case Map.get(args, :author_name) do
nil ->
Comment
author_name ->
from(c in Comment,
join: u in assoc(c, :author),
where: ilike(u.username, ^"%#{author_name}%")
)
end
end
这里带有 scope 的 map 会跟你定义的 args 的 map 进行合并,然后统一传给 phoenix context 里的 query 函数。最后还有一个问题没有解决,刚刚说了,对于 :author 这种关联性的字段,用 helpers dataloader 很方便就解决了,但是对于一些聚合类的字段,如 favorited,这个函数并没有效果,那咋办呢?其实也很简单,我们模仿它写个自己的 helpers 就行了,我们定义个 custome_dataloader 最后调用 do_dataloader 时把需要的 column 传给 run_batch 即可。
defp do_dataloader(loader, source, resource, args, parent, opts) do
col = opts |> Keyword.get(:args) |> Map.get(:col)
args =
opts
|> Keyword.get(:args, %{})
|> Map.merge(args)
loader
|> Dataloader.load(source, {resource, args}, Keyword.new([{col, parent.id}]))
|> on_load(fn loader ->
result = Dataloader.get(loader, source, {resource, args}, Keyword.new([{col, parent.id}]))
{:ok, result}
end)
end
Dataloader.get 的最后一个参数是个 Keyword list, 调用 Dataloader 时,run_batch 会自动匹配这个 keyword 的 key
def run_batch(Favorite, favorite_query, :favorites_count, article_ids, repo_opts) do
query =
from(f in favorite_query,
where: f.article_id in ^article_ids,
group_by: f.article_id,
select: {f.article_id, count(f.id)}
)
results = query |> Repo.all(repo_opts) |> Map.new()
for id <- article_ids, do: Map.get(results, id, 0)
end
所以最后我们的 article type 是这样的:
object :article do
field :slug, :string
field :title, :string
field :description, :string
field :body, :string
field :tag_list, list_of(:string)
field :created_at, :string
field :updated_at, :string
field :favorited, :boolean do
middleware Middleware.Authenticate
resolve custom_dataloader(Blog, {:one, Blog.Favorite}, args: %{col: :favorited})
end
field :comments, list_of(:comment) do
arg :author_name, :string
resolve dataloader(Blog, :comments, args: %{scope: :article})
end
field :favorites_count, :integer, resolve: custom_dataloader(Blog, {:one, Blog.Favorite})
field :author, :profile, resolve: dataloader(Accounts)
en