这是一篇书评,同时也是笔记。年初到现在,看了不少技术图书,但这本 Unit Testing 是最让我震撼的。作者开篇就提到
学习单元测试不应该仅仅停留在技术层面,比如你喜欢的测试框架,mocking 库等等,单元测试远远不止「写测试」这件事,你需要一直努力在单元测试中投入的时间回报最大化,尽量减少你在测试中投入的精力,并最大化测试提供的好处,实现这两点并不容易。
这说出了我们这些老程序员的心声,短时间内学会一门语言和框架并非难事,而如何管理你的时间和精力,写出成功交付的项目,且让这些项目易维护,好扩展,这才是难点。大多数书谈的都是测试的基础知识,多是关于框架的使用,而这书完全不一样,讨论了这些问题:
- 测试覆盖率真的靠谱么?
- 单元测试的结构
- assert 输出,状态,协作这三者的区别
- 一个好的单元测试的 4 大支柱
- Mock 跟脆弱性的关系
- 为什么你的测试不应该跟实现细节耦合,可观测行为和实现细节的区别是什么?
- 单元测试和集成测试的区别?什么情况下该使用单元测试,什么情况下应该用集成测试?
- ……
测试覆盖率
所谓的测试覆盖率就是「测试时代码执行的行数 / 代码的总行数」,比如这个例子:
def is_string_long(s: str) -> bool:
if len(s) > 5:
return True
return False
def test_is_string_long():
assert is_string_long('a' * 6)
很明显的这个测试覆盖率在 3/4,但如果我们把代码改成
def is_string_long(s: str) -> bool:
return True if len(s) > 5 else False
def test_is_string_long():
assert is_string_long('a' * 6)
当你运行 pytest --cov=. 时,你会发现这时我们的测试覆盖率已经是 100% 了。我们并没有修改测试代码,仅仅是调整了一下我们的业务而已。
还有一种计算覆盖率的方法是计算分支覆盖率,如果查看上面这段代码的分支覆盖率,你会发现是 50%,分支覆盖率会略精确一些,但是依然保证不了验证了所有可能的情况。
总而言之,测试覆盖率是一个非常棒的负面指标,但却是一个不好的正面指标。意思就是测试覆盖率低于一定的程度,项目肯定有问题,但测试覆盖率极高,如 100%,也不一定就是好事。
什么是单元测试
在定义什么是单元测试时,作者介绍了两个流派,伦敦流派和古典流派。首先提到,单元测试具有以下三个属性:
- Verifies a small piece of code (also known as a unit)
- Does it quickly
- And does it in an isolated manner
但是对于什么是单元,以及隔离的具体是什么?两个流派争议很大。伦敦流派倾向于认为一个类是一个单元,而且所有外部的依赖除非是不可变的值对象,其他都应该 mock 实现,而古典流派则是以一个类或一组类作为一个行为单元,而且只有共享依赖用测试双打的方式。
伦敦流派的依赖替换
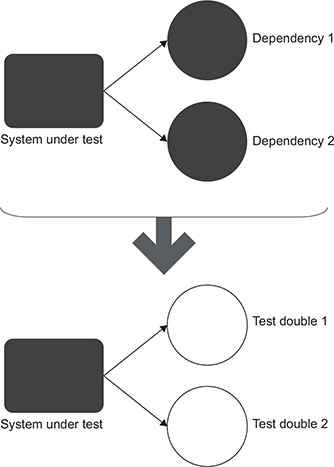
伦敦流派的测试代码和生产代码

古典流派的依赖替换
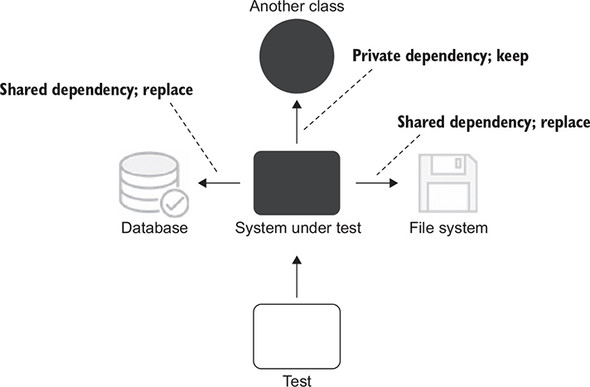
小结:
| school | Isolation of | A unit is Uses | test doubles for |
|---|---|---|---|
| London school | Units | A class | All but immutable dependencies |
| Classical school | Unit tests | A class or a set of classes | Shared dependencies |
作者更加倾向于古典流派,因为伦敦流派的那种方式很容易让实现细节与测试耦合。
所以用古典流派对于「单元测试」定义是这样的:
- Verifies a single unit of behavior
- Does it quickly
- And does it in isolation from other tests
单元测试的结构
首先看一段 Python 代码
def sum_two_numbers(first, second):
return first + second
def test_sum_two_numbers():
# arrange
first = 1
second = 2
# act
result = sum_two_numbers(first,second)
# assert
assert result == 3
关于单元测试结构的缩写有很多,但基本都离不开这三步,用 3A 模式来描述则,准备,动作,验证
虽然步骤很简单,但有一些原则可以遵守:
- 避免多个 arrange, act, assert,如果有多个 act,意味着有多个行为单元了,这就极大降低了代码的可读性和测试的可维护性,同时
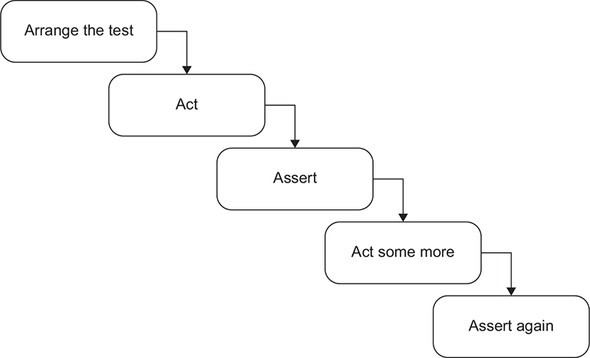
- 避免 if 语句
这个很好理解,多种情况完全应该隔离测试
- 使用测试夹具(test fixture)要谨慎,非常容易造成测试之间的耦合,以及降低了可读性
看一段 csharp 代码:
public class CustomerTests
{
private readonly Store _store; 1
private readonly Customer _sut;
public CustomerTests() 2
{ 2
_store = new Store(); 2
_store.AddInventory(Product.Shampoo, 10); 2
_sut = new Customer(); 2
} 2
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
bool success = _sut.Purchase(_store, Product.Shampoo, 5);
Assert.True(success);
Assert.Equal(5, _store.GetInventory(Product.Shampoo));
}
[Fact]
public void Purchase_fails_when_not_enough_inventory()
{
bool success = _sut.Purchase(_store, Product.Shampoo, 15);
Assert.False(success);
Assert.Equal(10, _store.GetInventory(Product.Shampoo));
}
}
为了节省代码,在单元测试之前,预先定义了商店的库存数量 15 个 shampoo,但这种简化是有代价的,极大的牺牲了可读性(当你在阅读单个测试的时候根本不清楚上下文有哪些),所以我个人在写 Elixir 代码时,单元测试除非必要,一般不用测试夹具,一般不做 setup。而在做集成测试时,也尽量把测试夹具的命名成声明式的,并直接写在每个测试的上方,如:
describe "list alive payment_methods" do
setup ~w(import_three_payment_methods enable_one_weixin_payment_method)a
@tag :integration
test "success" do
assert length(Pay.list_alive_payment_methods()) == 1
assert length(Pay.list_alive_payment_methods(%{label: :weixin})) == 1
assert length(Pay.list_alive_payment_methods(%{label: :offline})) == 0
end
end
所以上面的哪个 csharp 例子也可以重构为:
public class CustomerTests
{
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
Store store = CreateStoreWithInventory(Product.Shampoo, 10);
Customer sut = CreateCustomer();
bool success = sut.Purchase(store, Product.Shampoo, 5);
Assert.True(success);
Assert.Equal(5, store.GetInventory(Product.Shampoo));
}
[Fact]
public void Purchase_fails_when_not_enough_inventory()
{
Store store = CreateStoreWithInventory(Product.Shampoo, 10);
Customer sut = CreateCustomer();
bool success = sut.Purchase(store, Product.Shampoo, 15);
Assert.False(success);
Assert.Equal(10, store.GetInventory(Product.Shampoo));
}
private Store CreateStoreWithInventory(
Product product, int quantity)
{
Store store = new Store();
store.AddInventory(product, quantity);
return store;
}
private static Customer CreateCustomer()
{
return new Customer();
}
}
单元测试的 4 大支柱
识别一个好的测试和写出一个好的测试,是两种完全不同的技能,后者需要前者,所以一个好的测试具备些什么属性呢?作者提到了 4 点:
- Protection against regressions
- Resistance to refactoring
- Fast feedback
- Maintainability
简单翻译一下:
- 防止回归
- 耐重构
- 反馈够快
- 可维护性好
1. 防止回归
这方面的得分主要看三个方面:
- The amount of code that is executed during the test
- The complexity of that code
- The code’s domain significance
代码库越大,隐藏的 bug 就越多,如果没有防止回归,修改很容易引发其他的破坏性变更,越难维护。
2. 耐重构
耐重构,也就是是测试不变红的情况对应用代码重构的难易度。重构通常是非功能性的,也就是说在不改变应用的可观测行为下修改代码: 增加可读性和降低复杂性。
假阳性:测试报错,但不是真的错。
狼来了是很可怕的,因为你会慢慢习惯这种错误,从而引发真正的 bug,什么导致了假阳性?测试和测试系统的耦合越多,就越容易造成假阳性。所以测试应该站在最终用户的角度来验证可观测行为,其他都应该被忽略。
两个属性的小结
与此同时还有个假阴性的概念,也就是说测试通过了,但是可观测行为是错误的。这个也非常可怕,因为开发人员特别容易忽略这类错误。
两者的关系:
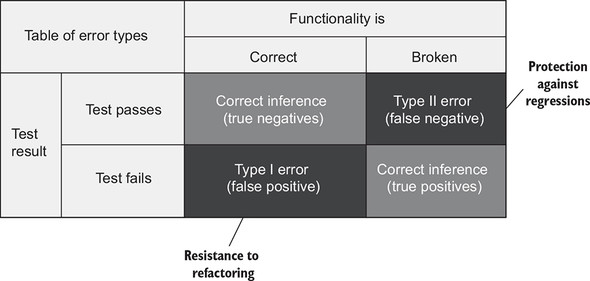
两者都是关于测试正确性,正确性的定义应该是
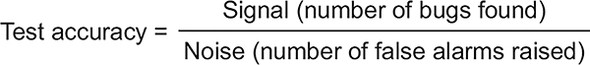
3. 快速反馈
测试运行的越快,大家就越愿意去运行
4. 可维护性
- 理解这个测试有多难
- 运行这个测试有多难
小结
在现实中建立一个包含 4 个支柱是不太可能的,因为前三个支柱会互斥:
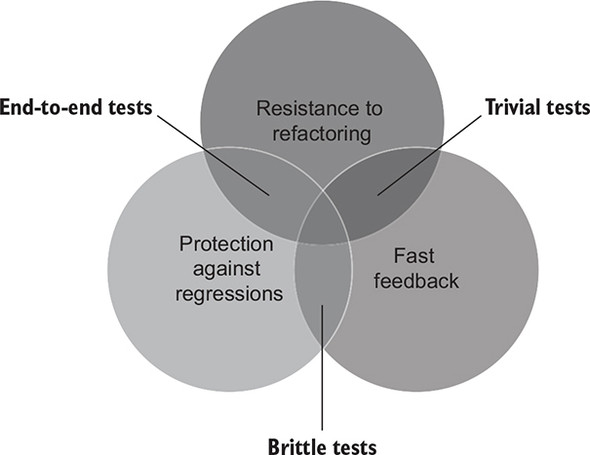
作者给的建议
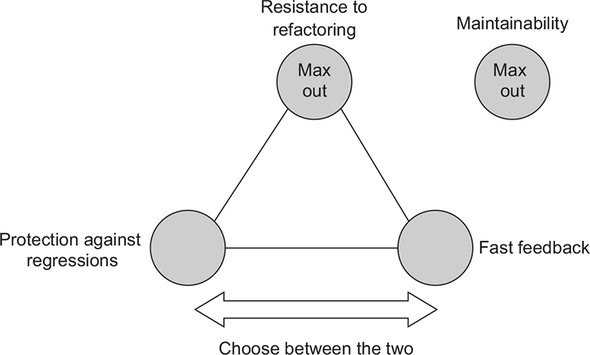
另外,可观测行为和公共的 API 应该一致,不应该暴露太多的实现细节:
public class User
{
public string Name { get; set; }
public string NormalizeName(string name)
{
string result = (name ?? "").Trim();
if (result.Length > 50)
return result.Substring(0, 50);
return result;
}
}
public class UserController
{
public void RenameUser(int userId, string newName)
{
User user = GetUserFromDatabase(userId);
string normalizedName = user.NormalizeName(newName);
user.Name = normalizedName;
SaveUserToDatabase(user);
}
}
重构之后
public class User
{
private string _name;
public string Name
{
get => _name;
set => _name = NormalizeName(value);
}
private string NormalizeName(string name)
{
string result = (name ?? "").Trim();
if (result.Length > 50)
return result.Substring(0, 50);
return result;
}
}
public class UserController
{
public void RenameUser(int userId, string newName)
{
User user = GetUserFromDatabase(userId);
user.Name = newName;
SaveUserToDatabase(user);
}
}
这个类最大的问题在于向客户端暴露了 NormalizeName 的这个实现细节,让更名时的步骤从一步变成了两步,这既不安全,也不好维护。
单元测试的风格
三种风格
- 基于输出的
- 基于状态的
- 基于通信的
| type | Output-based | State-based | Communication-based |
|---|---|---|---|
| Due diligence to maintain resistance to refactoring | Low | Medium | Medium |
| Maintainability costs | Low | Medium | High |
基于输出的因为只需要验证输出的值,所以他的可维护性和耐重构都是最好的,这也是为什么我喜欢 commanded 框架的原因,你会发现无论是 aggregate 还是 process manager 都是进行纯函数式测试的。
把测试重构的有价值
作者在第一章的时候定义了一个好的测试套件应该是:
- 被整合到了开发周期中
- 只针对你最重要的部分
- 它以最小的投入获取最大的回报
- 识别出有价值的测试,进而识别出低价值的测试
- 写出有价值的测试
识别需要重构的代码
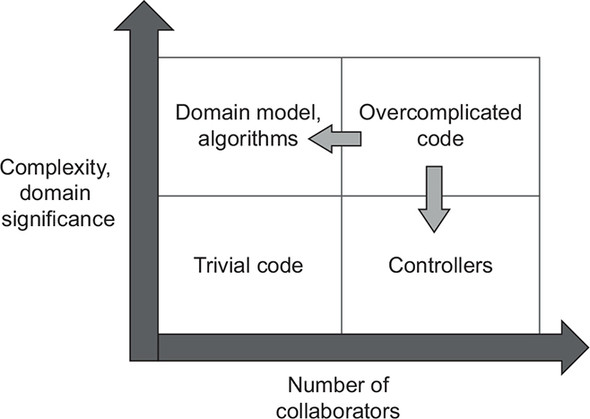
所有的生成代码都可以分为两个方面:
- Complexity or domain significance
- The number of collaborators
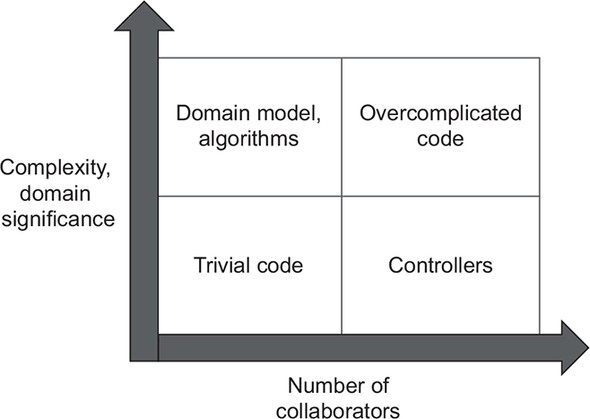
左上象限的代码是最值得测试的,这个地方的代码可以给你最大的回报。底层代码执行复杂且重要的逻辑,增强了测试对回归的保护,而且他们投入很少,是因为几乎没有协作者。而右上的代码是最难被测试的,但是理想情况下,右上应该是没有代码的,这类代码都应该被重构成左上和右下。为什么要设计聚合,其实就是为了减少协作。
References
- Mocks and explicit contracts « Plataformatec Blog http://blog.plataformatec.com.br/2015/10/mocks-and-explicit-contracts/