讲编程的书很多,说大脑认知的书也很多,而 《程序员的大脑》 是为数不多两者结合一起讲的好书。前司是一家创新驱动的脑与认知科学的公司,所以「认知科学」接触已久,而在读本书时,常有「啊哈」之感。
这书主要是从认知的角度讲了 4 个部分的内容:
- 认知科学如何帮助你更好地阅读代码
- 认知科学如何帮助你更好地对代码进行思考
- 认知科学如何帮助你写出更好的代码
- 认知科学如何帮助你更好地与他人协作
理论知识
工作记忆
这书涉及的认知科学概念并不多,核心概念可以用书里的一张图来描述

图7.1 当你学习新的信息时, 它首先由感官记忆(SM)处理, 然后由短时记忆(STM)处理。 新的信息随后被送到工作记忆中, 在那里你可以进行思考。 同时, 长时记忆(LTM)也在搜索相关信息。 如果发现了相关的信息, 这些信息也会被送到工作记忆中,以支持对新信息的思考。
工作记忆代表了大脑思考、形成新想法和解决问题的能力。我们可以把短时记忆比作计算机的 RAM, 把长时记忆比作硬盘。 按照这个比喻, 工作记忆就像大脑的处理器。
关于工作记忆更深的描述,前司的一篇公开课 《工作记忆背后的故事》 讲得很深入。其中核心点就是工作记忆的广度是有限制的,大部分人是 4,极少部分人才能到 7,另外就是工作记忆在处理信息的时候,同时也会在长时记忆里面搜索,所以这就是为什么事情你越熟悉,你处理起来就越快。
三重心智模型
这个模型的解释力还不错,但是读者若是同时了解下 「三重心智模型」,读本书可能会更轻松一些。

你的大脑工作机制,有三种工作机制:自主心智、算法心智与反省心智。
在自主心智部分,你不需要动用大脑太多算力,有来自先天的进化模块,比如,看到蛇就会害怕;也有来自后天的内隐学习模块。什么叫作内隐学习模块?当学习的技能成了肌肉本能,这就是内隐学习,无需再调用大脑太多算力。比如,小时候学会自行车,多年没骑,一旦再来,马上就会。自主心智部分还包括了前文提及的情绪模块,当一个情境出现,你究竟该笑还是哭?
算法心智则是传统智商测验考察的那些,比如反应快、算得准。
反省心智则是指人类对自主心智、算法心智监控、调节的机制。
— 引自 阳志平:九个角度理解疫情期间的人性
仔细读一下讲 「算法心智」和「反省心智」前因后果的书 《理性与反省心智 2011.2》 和这书大量引用的书 《Hypothetical Thinking: Dual Processes in Reasoning and Judgement-Routledge》 ,你会发现,工作记忆和短时记忆发生在算法心智层面,而长时记忆的调用与搜索发生在自主心智模块。因为进程 1(即自主心智)的主要功能之一就是根据先前的信念(反省心智相关)来确定问题的背景,从长时记忆中检索和应用相关的知识。
理解了这点,就会发现书中给的很多建议都非常实用了,比如第十章提到的改善你的内隐记忆可以让你解决问题的速度变快很多,原因就是自主心智的调用不需要耗费你过多的脑力;而学习一个新库的时候,可以多了解下他的目标以及诞生的前因后果,因为目标和信念属于反省心智的层面,用正确的信念,去指导消耗极高算法心智工作,可以极大的减轻你的认知负担。而这本书的核心要点就是减轻认知负担。
如何更好地阅读代码
读代码时的困惑及解决之道
要想更好更快地阅读代码,首先需要明白当我们读代码的时候都涉及了哪些认知活动,以及那部分会有负担。试看书中的几个二进制转换的例子:
apl 语言
2 2 2 2 2 ⊤ n
java
public class BinaryCalculator {
public static void mian(Integer n) {
System.out.println(Integer.toBinaryString(n));
}
}
basic
1 LET N2 = ABS (INT (N)) 2 LET B$ = ""
3 FOR N1 = N2 TO 0 STEP 0
4 LET N2 = INT (N1 / 2)
5 LET B$ = STR$ (N1 - N2 * 2) + B$
6 LET N1 = N2
7 NEXT N1
8 PRINT B$
9 RETURN
第一个程序看不懂主要是缺乏知识的原因,因为你大概率不知道 ⊤ 的含义,第二个程序,如果不明白 toBinaryString 具体的内部实现,那也会困惑,这是缺乏信息。第三个则是因为有太多变量和计算过程了,我们的工作记忆一下子就超载了。
知道了我们困惑的点,那么就可以针对性的解决,比如不熟悉语法,那么可能需要借助闪卡之类的手段间断式的学习语法,不熟悉一些内部实现,我们可能需要增加一些注释,而工作记忆超载,那么我们可能需要分块等等。
工作记忆超载之后怎么办?
书里介绍了很有意思的几种办法
1) 画出依赖图

具体步骤是
- 圈出变量,再用线链接起来
- 用另一种颜色圈出函数,将函数和定义关联起来,画一条线。尤其注意只有一次调用的方法或函数。
- 圈出类和实例(函数式里则是数据结构和数据)
这样的话,其实是有了一个可以参考的关于代码结构的信息,这种方法特别适合那种复杂的,相互联系的代码。
2) 画一个状态表

横坐标是变量,众坐标是步骤,中间是状态变动,这样的好处在于你只需要关心逻辑,而不需要记忆状态。这种方法特别适合需要大量计算的代码。
如何更好地对代码进行思考
加深对代码的理解
这一章作者讲了几个非常有意思的研究,其一是变量的 11 个角色:
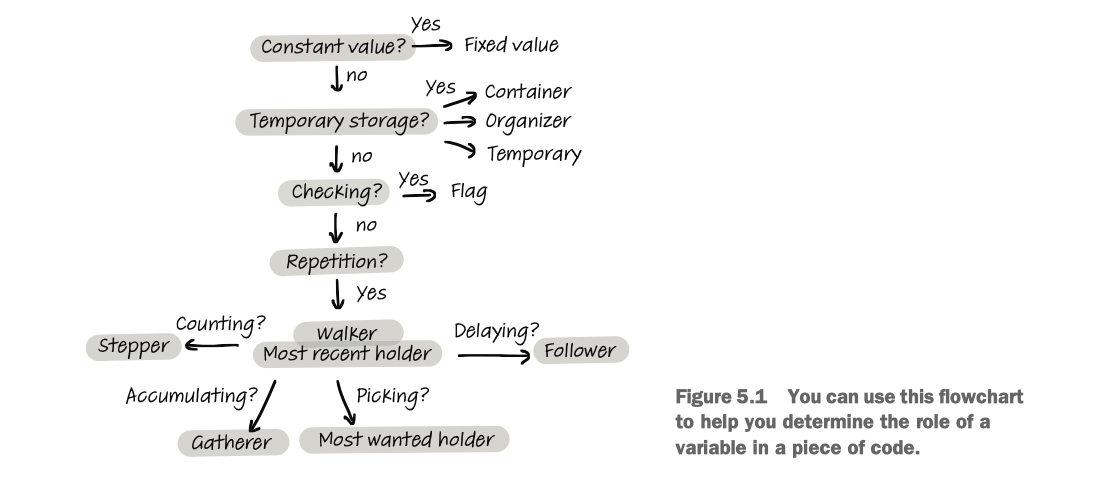
- 固定值(constant value): 常量
- 步进者(stepper): 比如循环迭代中的 i
- flag: 一个变量,标志某事已经发生或正在发生,典型例子是 is_set, is_available, 通常是个布尔值
- 步行者(walker): 步进者是在已知列表里迭代,而步行者是一个变量,但是是以一种未知的方式遍历数据结构
- 最近持有者:就一个数值的最新持有者,如读取文件的最新一行 line = file.readline()
- 最想要的持有者:就是最需要的持有者,典型例子是储存最小值/最大值或满足某个条件的第一个值的变量
-
收集器:
例:
sum = 0 for i in range(list): sum += list[i] - 容器:容纳多个元素的数据结构
- 跟随者:有些算法要求你跟踪前一个或后一个值,总是与另一个变量耦合
- 组织者:有是一个变量必须以某种方式进行转换,以便进一步处理
- 临时变量
这种角色的定义对于团队进行代码分享很有帮助,因为每种角色都有鲜明的特点。
另外还提了一下程序员对于项目从浅到深的理解一般分为这么 4 个阶段:
- 找到一个焦点
- 从焦点问题上扩展只是
- 然后从一组相关的实体中理解一个概念
- 理解跨越多个实体的概念。
很多情况下,你每一行代码都好理解,但是你却不清楚整个系统的实际结构,这主要是因为程序员本书有文本知识,而缺乏计划知识。计划知识代表着理解程序员在创建程序时的计划,或他们的目标是什么。